Il documento di approfondimento “Prevenzione e risposta a COVID-19: evoluzione della strategia e pianificazione nella fase di transizione per il periodo autunno-invernale” prevede diversi possibili scenari evolutivi della attuale pandemia, per ognuno dei quali è necessario considerare diverse contromisure. Allo stato attuale, oltre ai dati forniti quotidianamente in forma aggregata al Ministero della salute e a quelli già raccolti dall’Istituito Superiore di Sanità, esiste la necessità di individuare un minimo set di indicatori che possano essere condivisi tra le regioni e PA e siano utili a sostenere i decisori nelle strategie locali di contenimento ad hoc.
Un gruppo di lavoro AIE ha quindi rapidamente preso in considerazione le esperienze di alcune regioni e ha identificato le informazioni più rilevanti e più facilmente ottenibili da considerare in ogni Regione o PA, per la costruzione di un cruscotto regionale o di PA. Nel documento vengono riportati a titolo esemplificativo i dati disponibili per alcune regioni.
Le valutazioni fatte su base giornaliera sono la base per la comunicazione a diversi interlocutori e alla popolazione generale, soprattutto a supporto razionale di interventi adottati e se effettuate in modo coordinato anche per uno scambio diretto tra le Regioni e PA.
Per ogni indicatore è possibile stabilire delle soglie di allerta che giustificano azioni di sanità pubblica.
1 Indicazioni di tenuta del sistema di sorveglianza
1.1 Proporzione positivi
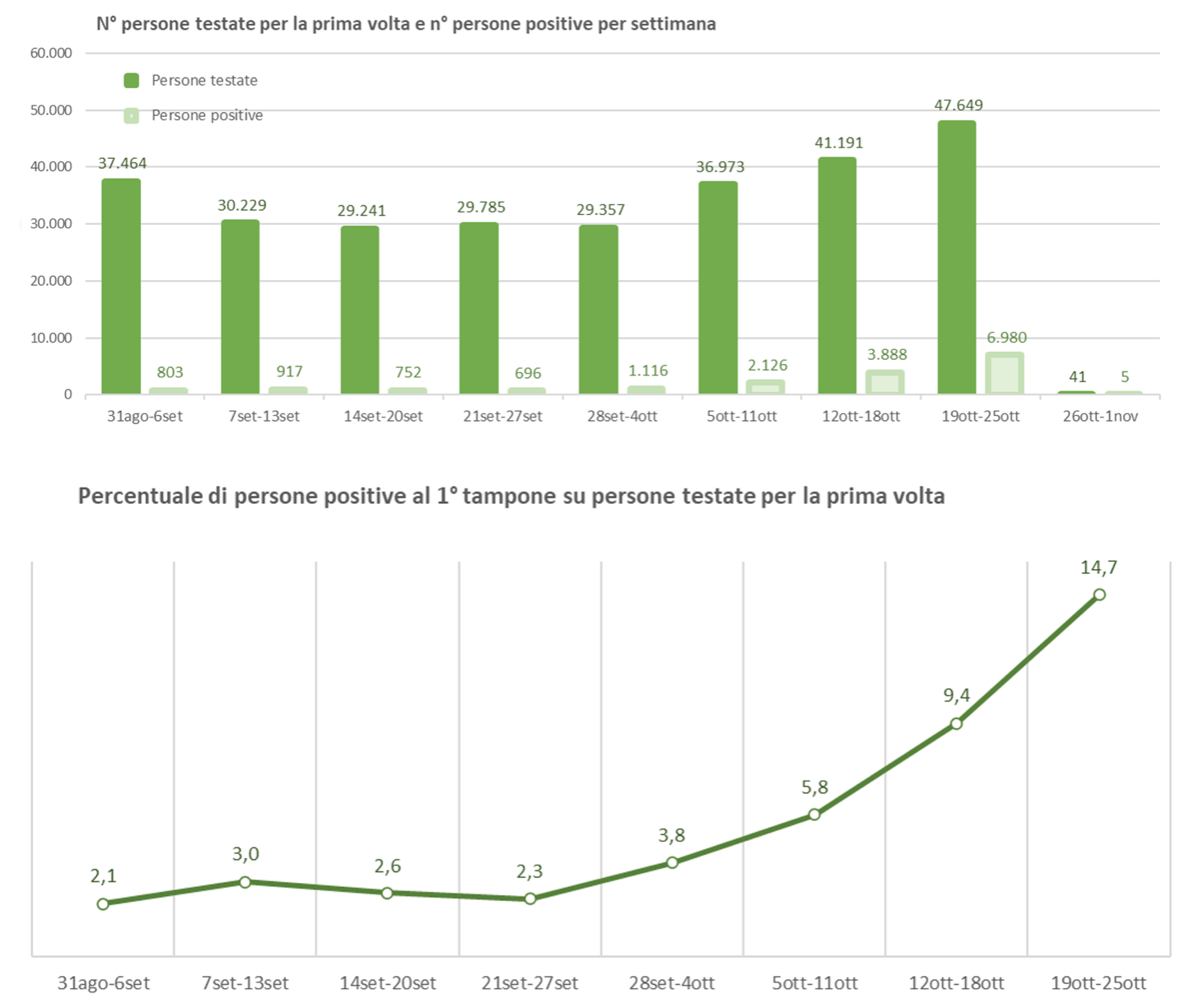
Sono fornite dalla proporzione dei primi tamponi positivi sul totale di tutti coloro che hanno fatto almeno un tampone. ECDC presenta i dati dei Paesi in UE usando la soglia del 4% per la proporzione di positivi. Con gli attuali livelli di incidenza proporzioni superiori al 10-12% sono considerate indicative di una bassa sensibilità del sistema.
1.2 Casi collegati a focolai
Un ulteriore indicatore è il numero di casi rilevati come associati a focolai epidemici.
Tale indicatore è già raccolto dal monitoraggio ministeriale ed indica la capacità di identificazione delle catene di trasmissione. Se la percentuale di casi non associati a catene di trasmissione noti aumenta, l’allerta è alta
Una criticità specifica è legata alla definizione di focolaio epidemico che riconosce due o più casi associati tra loro, anche in ambito familiare. Con tale definizione risulta sovra-rappresentata la quota di focolai familiari. Inoltre l’attuale aumento del carico di lavoro privilegerà il rintraccio dei soli contatti conviventi, più facili da raggiungere e testare e quindi il dato potrà esser molto distorto. Sembra opportuno effettuare analisi in cui si verifica la quota di casi collegati a focolai di dimensioni maggiori alle dimensioni medie delle famiglie in ogni regione. A livello nazionale il numero medio dei componenti in di un nucleo familiare in Italia è 2,3.
1.3 Ritardo di osservazione
Un’ulteriore verifica da fare è sull’intervallo temporale tra presunta data di contagio ed identificazione del caso (data di diagnosi). Attualmente i dati nazionali del sistema di sorveglianza dell’Istituto Superiore di Sanità (ISS) indicano che la mediana del tempo che intercorre dalla data inizio sintomi alla diagnosi è di circa 3 giorni, a questi vanno aggiunti i 6 giorni di probabile tempo di incubazione ed almeno un giorno di attesa prima di rivolgersi al medico. Inoltre la data di segnalazione, se diversa dalla data di diagnosi, va considerata. Una sofferenza del sistema porterà ad un allungamento dei tempi di accertamento, ma soprattutto la conoscenza di tale intervallo è importante per prevedere i tempi di effetto di eventuali nuove contromisure adottate e la crescita di casi, ospedalizzazioni e ammissioni in ICU nel frattempo.
2 Indicatori di diffusione
Per descrivere la diffusione dell’epidemia nella popolazione l’indicatore di base fondamentale già in uso è l’incidenza di casi confermati (7/14 giorni) per 100.000 abitanti.
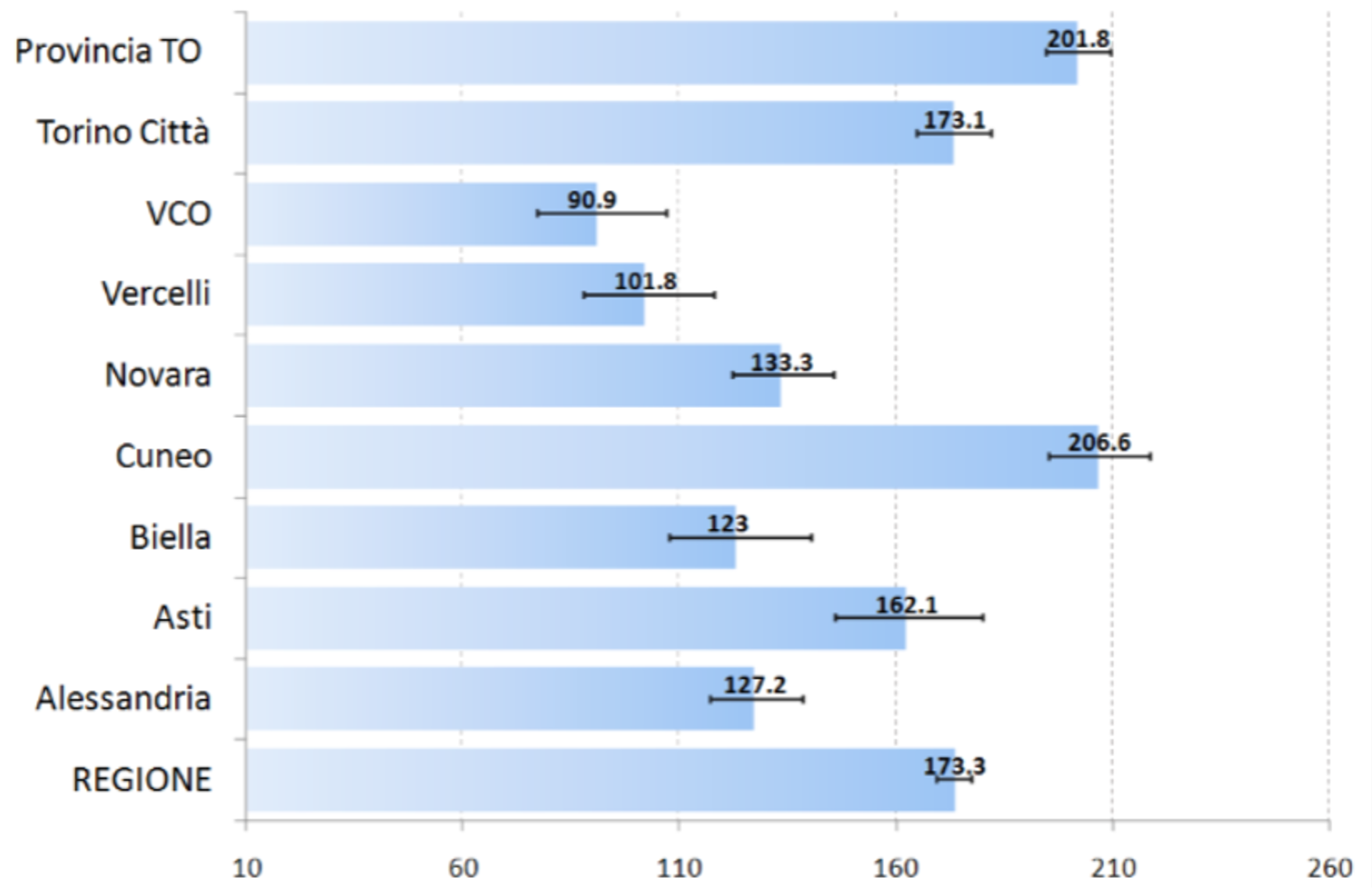
2.1 Incidenza per provincia o per Comune
L’incidenza è considerata, per ogni specifica settimana, per area geografica, come ad es. nel confronto tra province, come nell’esempio seguente, in cui sono riportati anche i valori della stima di precisione del valore numerico osservato:
2.2 Variazione percentuale per Provincia o per Comune
Affiancato al dato di incidenza puntuale è raccomandabile utilizzare un dato di variazione % rispetto al periodo precedente, per avere un’idea dell’andamento nel tempo della situazione, come proposto dalle regioni Piemonte e Puglia. L’idea è quella che due situazioni di grande diffusione potrebbero essere interpretate diversamente se in miglioramento o in peggioramento rispetto al periodo precedente. Per piccole aree ci potrebbe essere un fenomeno oscillatorio casuale da tenere in considerazione.
Variazioni rilevanti nella frequenza locale vengono evidenziate da un confronto dell’ultima settimana con le due precedenti. Come nell’esempio qui sotto che riguarda tre Comuni della Provincia di Bari.

Anche in questo caso è importante per i decisori valutare se incrementi localizzati di incidenza sono dovuti a singoli focolai circoscrivibili, per cui il dato di maggior diffusione non è riferibile all’intera comunità locale.
È utile, inoltre, per una migliore differenziazione del rischio, considerare anche il numero di casi collegati vs. sporadici, ma anche qui la definizione di focolaio epidemico con due soli casi può essere fuorviante e va verificata per focolai di maggiori dimensioni. Ad esempio per evitare di individuare alcune zone come critiche a seguito di focolai nelle residenze per anziani si suggerisce di valutare separatamente i casi in RSA/CRA. Ovviamente si dovrà fare un monitoraggio ad hoc per valutare la trasmissione in questo ambito. Qualsiasi modifica nelle procedure di identificazione dei casi (screening o contact-tracing) e dei focolai epidemici può indurre valutazioni distorte circa la diffusione della pandemia,
E’ raccomandabile organizzare le informazioni calcolate su base comunale per diversi raggruppamenti geografici. Ogni intervento e misura di contenimento è da valutare in stretta connessione con i decisori politici rispetto ai “legami” tra territori che influenzano gli scambi e le connessioni. Sulla base di queste analisi può essere scelto il raggruppamento più opportuno per l’analisi del rischio. Più piccola è l’unità , più si può essere selettivi nell’applicare misure restrittive, ma il rischio è di essere imprecisi perché pochi casi di differenza possono fare oscillare molto le stime.
2.3.Sistemi georeferenziati
I dati georeferenziati all’indirizzo di residenza permettono di produrre mappe ed elaborazioni frequenti.

Uno dei problemi della nuova ondata è l’interessamento delle aree urbane (es Roma, Milano, Napoli), quindi oltre alle mappe settimanali dei tassi di incidenza per comuni ci si dovrebbe concentrare in particolare su analisi per sottoaree all’interno di grandi comuni.
2.4 Per età
L’incidenza calcolata stratificando per classi di età permette di individuare criticità specifiche come l’aumento dei casi tra gli anziani o nelle scuole. Ad esempio, nel grafico riportato qui sotto, l’incremento maggiore risulta nella classe di età 14-18 anni che sembra prevalere su tutte le altre classi di età. L’osservazione può essere rilevante per le misure di contrasto alla diffusione.
 L’allerta cresce all’aumentare dell’incidenza tra gli anziani
L’allerta cresce all’aumentare dell’incidenza tra gli anziani
2.5 Severità della malattia
Alla diffusione dell’epidemia è poi utile aggiungere informazioni relative alle caratteristiche dei casi.
La proporzione di casi sintomatici può dare un segnale di allerta se è in aumento.
Un grafico su scala logaritmica del numero di casi che richiedono assistenza ospedaliera e del numero dei ricoverati in terapia intensiva fornisce la misura della proporzione di incremento e permette di calcolarne la crescita.
I tempi di saturazione delle strutture di assistenza possono essere calcolati tenendo presente la velocità di raddoppio dei ricoveri e il fatto che l’immagine di diffusione che la sorveglianza ci restituisce è ritardata di un numero di giorni (vedi punto 1.3) dovuto ai tempi di contagio, di sviluppo dei sintomi, di diagnosi e di trasmissione dei dati. Il ritmo di ospedalizzazione e di accesso a ICU si manterrà per almeno un numero di giorni pari a quelli del ritardo di osservazione successivi a qualsiasi misura di contrasto.
Tabella riassuntiva dei dati del cruscotto proposto
| Indicatore | Modalità di calcolo | Frequenza Raccomandabile | Ambito geografico |
|---|---|---|---|
| Sistema | |||
| Proporzione tamponi positivi | Numero primi tamponi positivi / totale di tutti coloro che hanno fatto almeno un tampone | Quotidiano, per stessa data prelievo | Regione, Provincia, Distretto, Comune |
| Casi collegati a focolai | Numero nuovi casi collegati a focolai/Tutti nuovi casi nel periodo | Casi identificati nell’arco di una settimana. Analisi separata con e senza RSA | Regione, Comune |
| Ritardo di osservazione | Intervallo tra data di inizio sintomi e data prelievo/diagnosi e Intervallo tra data prelievo/diagnosi e segnalazione | settimanale. Andamento per le ultime 4 settimane | Regione, Dipartimento di Prevenzione (Az. Usl), Distretto |
| Diffusione | |||
| Incidenza di casi confermati per 100.000 abitanti in 7/14 gg | Numero di nuovi casi diagnosticati/popolazione residente | Quotidiano e settimanale per data diagnosi | Regione, Provincia, Distretto, Comune |
| Mappe di distribuzione dei casi | Numero di nuovi casi per indirizzo di residenza | Quotidiano e settimanale per data diagnosi | Comuni in mappa regionale e sottoaree metropolitane |
| Incidenza per età | Numero di nuovi casi per ciascuna di 9 classi di età | Settimanale, da agosto in poi | Regione, Provincia, Distretto, Comune, sottoaree metropolitane |
| Severità | Numero di ospedalizzati, numero di pazienti in ICU | Quotidiano | Regione, Provincia, Distretto |

