
Questa settimana è stato presentato per la prima volta pubblicamente l'articolo "On the Dangers of Stochastic Parrots", letteralmente "Sui pericoli dei pappagalli stocastici", durante la conferenza ACM Fairness Accountability and Transparency. L'articolo solleva i problemi di natura ambientale, sociale ed etica connessi all'impiego di modelli statistici del linguaggio che utilizzano database di dimensioni sempre crescenti, impiegati nei motori di ricerca, negli assistenti vocali e nei traduttori automatici. Lo studio porta le firme delle due ex coordinatrici del gruppo di etica e intelligenza artificiale di Google, Tminit Gebru e Margareth Mitchell, e di due linguiste della University of Washington, Emily Bender e Angelina McMillan-Major, e ha causato il licenziamento delle prime due dalla società tecnologica. La vicenda ha avuto grande clamore e ha messo in discussione la volontà di Google di contribuire allo sviluppo di sistemi di machine learning che siano inclusivi e rispettosi anche verso le minoranze. Immagine tratta da Pixnio.
Si è conclusa mercoledì la ACM Conference on Fairness, Accountability, and Transparency (FAccT), promossa dalla Association for Computing Machinery, durante la quale è stato presentato per la prima volta l’articolo “On the dangers of Stochastic Parrots”. L'articolo è all’origine del licenziamento delle ricercatrici Timnit Gebru prima e Margareth Mitchell poi da parte di Google, dove co-dirigevano il gruppo di etica e intelligenza artificiale.
I “pappagalli stocastici” cui si fa riferimento nel titolo, in inglese “stochastic parrots”, sono i cosiddetti large language models, i modelli statistici del linguaggio che si basano sull’apprendimento da grandi database di testi, presi prevalentemente da internet. Con questa espressione le autrici vogliono sottolineare che questi sistemi non hanno alcuna comprensione del significato delle parole o delle espressioni che generano, perché non sono costruiti per averlo, ma piuttosto individuano degli schemi verbali ricorrenti nei dati e li “ripetono”.
La notizia del licenziamento di Gebru il 3 dicembre ha avuto grande risalto nei media di tutto il mondo. Gebru infatti è una delle esponenti di maggior rilievo nel campo dell’etica dell’intelligenza artificiale, soprattutto riguardo ai diritti di inclusione delle minoranze e dei loro punti di vista nelle grandi società tecnologiche e nei sistemi di intelligenza artificiale che queste sviluppano. Gebru ha ottenuto nel 2017 un dottorato presso lo Stanford Artificial Intelligence Laboratory. La sua tesi è culminata in una pubblicazione sui Proceedings of the National Academy of Sciences in cui viene mostrato come l’analisi automatizzata delle immagini delle auto parcheggiate fuori dalle abitazioni in diversi quartieri delle città americane, raccolte da Google Street View, permetta di fare inferenze sulla loro composizione demografica e orientamento politico. Successivamente ha lavorato nel gruppo Fairness Transparency Accountability and Ethics in AI di Microsoft Research, ha fondato il gruppo Black in AI, che si impegna a favorire l’ingresso di studenti e ricercatori neri nel campo dell’intelligenza artificiale, ha promosso iniziative di formazione nel campo del machine learning nelle scuole superiori e nelle università africane, in particolare in Etiopia, il suo paese di origine, partecipando ad Addis Coder. Nel 2018 Gebru ha collaborato con Joy Buolamwini, allora studente di dottorato all’MIT media lab, al progetto Gender Shades, che ha mostrato come i sistemi di riconoscimento facciale sviluppati dalle maggiori società tecnologiche fatichino molto a identificare i volti di donne nere, mentre non hanno problemi con gli uomini bianchi (il motivo è che gli archivi di immagini su cui vengono allenati contengono più volti di uomini bianchi che di donne nere). Il progetto è stato raccontato nel documentario Coded Bias, uscito negli Stati Uniti nel settembre del 2020.
All’origine del licenziamento di Gebru, che Google ha fatto passare per dimissioni in questa lettera resa pubblica poco tempo dopo da Jeff Dean che dirige le divisioni Google Research e Google Health, c’è la richiesta della società di non sottoporre l’articolo in questione alla conferenza ACM FAccT oppure di cancellare il proprio nome dall’elenco degli autori (così come quello di tutti i dipendenti Google coinvolti). Secondo la società infatti l’articolo non raggiungeva il livello richiesto per la pubblicazione poiché ignorava una parte rilevante della letteratura scientifica sull'argomento.
L’articolo si concentra sulle conseguenze sociali dell’applicazione dei large language model. Questi modelli sono alla base dei motori di ricerca, incluso quello usato da Google, dei sistemi per il riconoscimento vocale automatico, usati per esempio dagli assistenti come Google Home o Alexa, dai traduttori multilingue o dai chat bot.
Le autrici riflettono sull’impatto ambientale ed economico del training di questi modelli, sul rischio di rinforzare i punti di vista appartenenti ai gruppi egemonici nella società a discapito delle minoranze, che sono poco rappresentate nei dati su cui questi sistemi vengono allenati, esattamente come accade nei sistemi di riconoscimento facciale.
Secondo Google le autrici non fanno riferimento, ad esempio, a una serie di studi che propongono delle tecniche di training a basse emissioni, attraverso l’utilizzo di hardware e software più efficienti.
Il licenziamento di Gebru ha avuto una serie di conseguenze importanti.
Pochi giorni dopo la notizia, il gruppo Google Walk Out ha pubblicato una lettera #IStandWithTimnit in cui chiedeva alla società di chiarire l’accaduto sia internamente che esternamente, sottolineando che Gebru era una delle poche donne di colore impiegate dalla società (solo l’1,6% dei dipendenti Google appartiene a questa categoria) e una delle poche ricercatrici che esercitava pressione dall’interno dell’industria tecnologica per garantire lo sviluppo di sistemi di intelligenza artificiale etici ed inclusivi. A oggi la lettera è stata firmata da quasi 2700 dipendenti di Google e oltre 4300 accademici.
Google Walk Out è un gruppo nato a novembre 2018 quando aveva invitato i dipendenti e i fornitori di Google a uscire dai propri uffici per protestare contro una cultura aziendale caratterizzata da una gestione delle denunce di molestie sessuali troppo timida, dalla mancanza di trasparenza e da comportamenti discriminatori verso le minoranze (e ancor più verso le cosiddette minoranze intersezionali, gruppi di persone che hanno caratteristiche, come etnia, religione, disabilità, identità di genere non binaria, classe sociale o aspetto fisico, ciascuna delle quali è singolarmente oggetto di discriminazione). A quella iniziativa avevano partecipato oltre 20 000 persone in 50 città americane.
Pochi giorni fa, poi, Google Walk Out ha pubblicato un’altra petizione diffusa sui social media con l’hashtag #MakeAIEthical, in cui chiede:
- alle conferenze di intelligenza artificiale di rifiutare la sponsorizzazione di Google e di non accettare articoli modificati dai legali delle società tecnologiche
- alle università di non accettare fondi da Google finché la compagnia non si impegnerà a rispettare standard minimi di trasparenza e integrità
- ai ricercatori di rifiutare proposte di lavoro provenienti da Google
- allo stato americano di potenziare la protezione dei whistleblower del mondo tecnologico.
La conferenza ACM FAccT aveva deciso autonomamente già il 26 febbraio di cancellare Google dalla lista degli sponsor, che comprende tra gli altri Facebook AI, DeepMind, OpenAI, IBM. La decisione era stata motivata dal licenziamento di Margareth Mitchell avvenuto il 19 febbraio. Mitchell è stata estromessa dai suoi account aziendali dopo aver inviato all’ufficio pubbliche relazioni di Google questa lettera in cui esprimeva il suo dissenso verso il licenziamento di Gebru, che lei stessa aveva chiamato a Google, descrivendo le implicazioni più ampie di quella decisione per lo sviluppo di un’intelligenza artificiale basata su principi etici.
Google da parte sua ha cercato di rimediare ristrutturando le procedure di revisione degli articoli scientifici prodotti dai propri ricercatori e nominando Mariana Choak, una delle poche donne nere in posizione apicale nella società, a coordinare questa attività. Tuttavia molti giudicano questa reazione ampiamente insufficiente rispetto all’accaduto.
Ma qual è il contenuto dell’articolo? Si tratta sostanzialmente di una revisione della letteratura riguardante i risvolti economici, sociali ed etici dei large language models. Con l'espressione language model le autrici si riferiscono a sistemi in grado di prevedere quale espressione (lettera, parola, o frase) è più probabile che appaia in una certa posizione all’interno o alla fine di un testo. L'aggettivo large, invece, indica che questi sistemi apprendono da database di grandi dimensioni e utilizzano un grande numero di parametri per codificare questo apprendimento. Nel primo numero di questa newsletter avevamo parlato dell’ultimo generatore di linguaggio naturale sviluppato dalla società OpenAI, GPT-3, che ricevendo come input il cosiddetto prompt restituisce un testo scritto che risponde a una domanda o semplicemente prosegue il discorso. GPT-3 è un esempio di large language model, ma negli ultimi due anni ne sono stati sviluppati molti che vengono allenati su campioni grandi centinaia di gigabyte e usano centinaia o addirittura migliaia di miliardi di parametri per funzionare, come nel caso di Switch-C, l’ultimo algoritmo sviluppato da Google Brain.
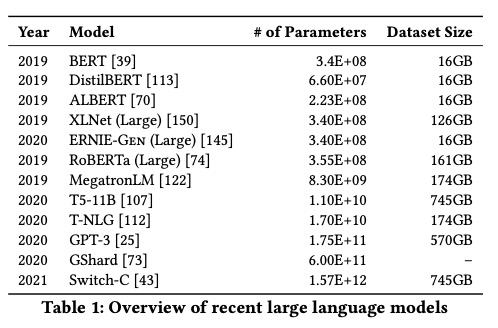
Le autrici analizzano tre aspetti critici che derivano dall’utilizzo di questi sistemi, e che rischiano di essere aggravati dalla tendenza a sviluppare modelli ancora più grandi di quelli disponibili ora.
Il primo aspetto critico è l'impatto ambientale di questi sistemi. In media una persona emette 5 tonnellate di CO2 ogni anno, mentre l’addestramento di un modello di linguaggio della famiglia dei Transformer (reti neurali con architettura particolare) comporta l’emissione di 284 tonnellate di CO2. Appartiene alla famiglia dei Transformer anche BERT, il sistema utilizzato dal motore di ricerca di Google, e il suo allenamento comporta l’emissione della stessa quantità di CO2 emessa da un volo aereo da una costa all’altra degli Stati Uniti. Le autrici osservano che i cambiamenti climatici causati dall’emissione di gas serra hanno maggiore impatto su territori e popolazione che beneficiano molto meno di questi sistemi rispetto ai paesi che li sviluppano, semplicemente perché parlano lingue che raramente sono incluse in questi modelli e non hanno i mezzi finanziari per poter avere accesso ai dispositivi che li sfruttano (gli assistenti come Google Home o Alexa). Si chiedono poi se l’aumento delle dimensioni di questi modelli, e quello conseguente in termini di emissioni, è giustificato da un guadagno proporzionato nell'accuratezza e concludono che la risposta a questa domanda raramente viene considerata negli articoli scientifici.
Il secondo problema che considerano potrebbe essere sintetizzato con l'espressione "tanti dati ma pochi punti di vista". Le grandi dimensioni dei database di testi su cui questi modelli di linguaggio vengono allenati non garantiscono infatti inclusione. Prendiamo il caso di GPT-3: l’apprendimento è basato su una versione filtrata del database Common Crawl, che percorre ogni mese internet sulla base dei collegamenti tra le pagine e costruisce un archivio dei testi che contiene. Il filtro è costruito in modo che selezioni i contenuti di Wikipedia, Reddit oltre agli estratti di libri. Succede quindi che i punti di vista più rappresentati siano quelli degli autori di Wikipedia, di cui solo l’8%-9% sono donne, e degli utenti di Reddit, prevalentemente maschi bianchi e giovani residenti nelle aree urbane degli Stati Uniti. In generale i testi raccolti con la tecnica del crawling hanno una distorsione: le voci dissonanti tenderanno a essere meno collegate a quelle dominanti e dunque meno raggiungibili seguendo i link tra le pagine in rete.
Come conseguenza questi sistemi incorporano nei loro output diversi tipi di pregiudizi diretti verso i gruppi meno rappresentati nei database di allenamento e ancora di più verso le minoranze intersezionali. Le autrici però osservano che la valutazione di queste distorsioni non può essere facilmente automatizzata, ma piuttosto deve essere realizzata caso per caso considerando il tipo di applicazione e assumendo il punto di vista di diversi gruppi sociali. I limiti dei sistemi automatici di auditing degli algoritmi sono stati messi in evidenza anche da altri osservatori.
Allo stesso modo l’idea di depurare dai contenuti “tossici” i dati di allenamento comporta dei rischi. Il database Colossal Clean Crawled è ottenuto da Common Crawl cancellando le pagine che contengono una o più delle 400 parole contenute in una lista standard di parole oscene, violente e offensive. La lista contiene prevalentemente parole riferite al sesso, insieme ad alcune espressioni razziste e del suprematismo bianco. Se questa operazione permette di eliminare con una certa efficienza le pagine di siti pornografici o contenenti discorsi d’odio, con altrettanta efficienza cancellerà le pagine web frequentate dalla comunità LGBTQ e questo avrà come conseguenza l’esclusione del punto di vista di questo, come di altri gruppi marginalizzati.
Il secondo aspetto problematico denunciato nell'articolo riguarda il fatto che essere in grado di generare testi che appaiono fluidi e verosimili non equivale ad averne compreso il significato. Questa è una conclusione abbastanza condivisa da diversi esperti (per esempio qui) e le autrici si chiedono se il fatto che questi modelli con miliardi di parametri e centinaia di gigabyte di dati da cui apprendere riescano a passare dei test pensati per valutare il livello di comprensione del significato del linguaggio sia un passo avanti o invece richieda una pausa per capire se questa è la direzione in cui l’area di ricerca deve proseguire.
Le autrici infine fanno delle proposte per curare alcuni di questi limiti. La più interessante tra queste è quella di usare database di allenamento commentati e documentati, ispirandosi alle tecniche delle scienze archivistiche, e limitarsi a dimensioni che possano essere curate in questo modo. Questo lavoro di documentazione dovrebbe essere preso in considerazione nell’analisi dei costi preliminare a qualunque tipo di progetto
Per ricevere questo contenuto in anteprima ogni settimana insieme a sei consigli di lettura iscriviti alla newsletter di Scienza in rete curata da Chiara Sabelli (ecco il link per l'iscrizione). Trovi qui il testo completo di questa settimana. Buona lettura, e buon fine settimana!

